1.1 Overview:
By using natural language processing Technology, computer can identify and segment words by using dictionary and appropriate algorithm. However, it is not easy to segment Chinese. Different from English, there are no space between Chinese words in a sentence. Therefore, many problems happened such as misidentified name and ambiguity. Thus, the algorithm used for segmentation should be accurate and the dictionary must be rich. The objective of this research is to build up a dictionary and used it with an open source segmentation algorithm to improve accuracy. Moreover, unique classification and self-learning algorithm based on entropy and supervised learning has been designed. Several types of processing tools can be used to build up our dictionary: cluster, segmentation, key words, POS, new word, sentiments, classify, etc. The advance usage of all these functions will be designed in the future.1.2 Tools:
- Programming language: Python, SQL
- Database: MySQL
- Server: Apache HTTP Server
- Libraries: Jieba, Pypinyin, NLPIR
2.1 Corpus selection:
In order to build up a dictionary, selection of corpus is important. The quality of dictionary depends on how much corpus is processed. Huge amount of corpus can enrich the dictionary. For this research, the corpus of five million tweets is downloaded from ‘Natural Language Processing & Information Retrieval Sharing Platform’ Furthermore, in order to enhance the performance of the classification algorithm, various corpus with high quality must be collected and utilized. Unfortunately, because of limited time, totally fitted corpus have not been collected and only small scale corpus with low quality are adopted.2.2 Dictionary building up:
Chinese natural language processing can help to segment words from corpus and tag part-of-speech (POS) for each word. After both processes above, a dictionary will be built up with pattern [word, frequency, POS] and stored in database. One problem occurred that the whole 5 million tweets are so large that a large amount of time (over 24 hours) are needed. Therefore, the program has been designed to be a stop-allowable process by adding an interrupt to the code. The program can resume at which it stopped last time. Approximately it spent 28 hours to complete building dictionary from 1 million tweets. Distributed system will be developed for the algorithm to deal with huge corpus in the future.2.3 Classification algorithm:
Classification, especially for Chinese, contains tremendous difficulties if there is no fundamental classified dictionary. Because computer cannot understand the meaning of the word or phrase, only human can fulfill the work. This algorithm is only an attempt on solving the problem.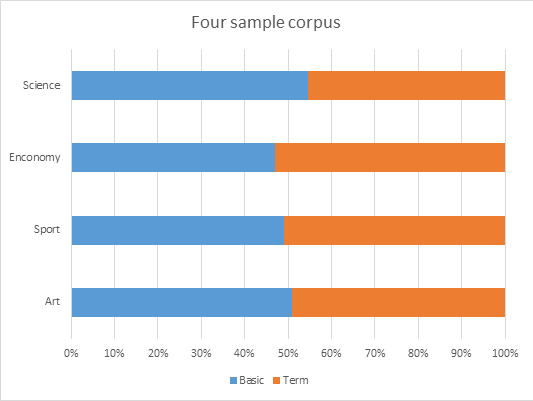
3.1 Result:
The table of below presents the result of the Weibo tweets processing. One million tweets had been processed.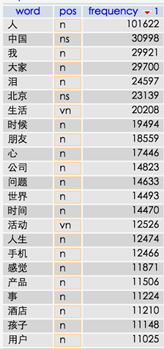
The word segmentation performance of Jieba is improved after replaced above dictionary. The word ‘长文’ and ‘完美主义者’ are recognized by the new dictionary.

Word segmentation by using original dictionary

Word segmentation by using new dictionary
We are pleased to be able to join in this summer exchange program. It is a huge opportunity for us. This is the first time we visit UCLA. The campus is beautiful and we work there. There are three members in our group. One member said he even did not want to leave this place. Our work mainly deal with huge data. It is a challenging project. We have overcome many problems within our research. We were satisfied with the result. It is really a good experience.