Report 1 -- Smart E-mail Reply Robot
Advisors: Giovanni Pau, Rita Tse
Group Members: Ben Wang, Nick Lin
As a smart reply bot, it should have the ability to communicate with human. That means it needs to understand what people are said and can generate a related reply. Also, when it can’t understand inputs, it should point out that it could not understand instead of talk nonsenses. We need to train a useable model and deploy it into a server, after that, people could use this service when using mail system and will get some auto reply from the reply bot.
1.1 Background
With the improvement of deep learning technology, people are seeking more intelligence life. Communication, as an important part of humans’ daily life, cost a lot of our patient, free people from easy communications can let work more efficient. In our project, we are using smart reply bot to help people handle easy mail reply. When using this service, smart reply bot will help people reply emails automatically, which can free people from boring work, especially these easy but repeat ones.
1.2 Objectives and Main Tasks
Our goal is to develop an AI program that can reply to some simple e-mails. As a smart reply bot, it should have the ability to communicate with a human. That means it needs to understand what people are said and can generate a related reply. Also, when it can’t understand inputs, it should point out that it could not understand instead of talk nonsenses. We need to train a useable model and deploy it into a server, after that, people could use this service when using a mail system and will get some auto reply from the reply bot.
So, our main task is divided into three steps. The first step is to find and implement a proper model to train. The second step is to generate a dataset to train the model. And the third step is to train the model and test it.
1.3 Project description
We are using Papaya Conversational Dataset [1] as the training dataset. And RNN with LSTM as the training structure. In this way, we have a robot that can make responses to e-mail contents.
2. Design and Implementation
Currently, there are many models for neutral language processing, i.e. NLP. We compared many models, finally chose the new seq2seq model based on dynamic RNN, based on TensorFlow [2].
2.1 Model design
Seq2seq is a network with encoder-decoder structure. The input of the model is a sequence, the output is also a sequence [3]. As the input sequence and the output sequence have variable length, it is very suitable for us to implement it on our e-mail reply robot.
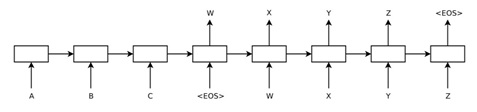
Figure 2.1.1. the structure of seq2seq model
The included code in the model we have referred to before is lightweight, high-quality, production-ready, and incorporated with the latest research ideas [2]. NMT models vary in terms of their exact architectures, in the model we are currently using, we consider it is a deep multi-layer RNN, in precise, 4 layers, which is unidirectional and uses LSTM as a recurrent unit.
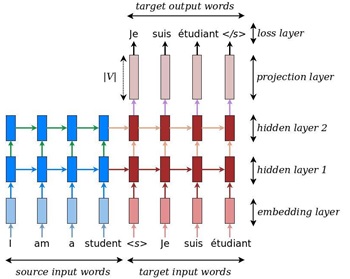
Figure 2.1.2. example of a deep recurrent architecture
2.2 Datasets
The choose of datasets is crucial for the success of a model as the model is “learning” directly from the datasets. Also, the size of a dataset is important, as a model has a capacity limit, that is how much data it can learn or remember. When the number of layers, number of units, type of RNN cell and the encoder/decoder length is fixed, it’s mainly the vocabulary size that impacts your model's ability to learn, instead of the number of training samples.
The dataset we are using is from the internet, which is called Papaya Conversational Data Set. It cleaned many datasets we can browse from the internet and data inside it is well-organized [1].
The data are composed of two sets: the first set was handcrafted, and the author created the samples in order to maintain a consistent role of the chatbot, who can therefore be trained to be polite, patient, humorous, philosophical, and aware that he is a robot named Papaya; the second set was cleaned from some online resources, including the scenario conversations designed for training robots, the Cornell movie dialogs, and cleaned Reddit data.
Then, after cleaning the data, the data files in this data set were preprocessed with NLTK tokenizer so that they are ready to feed into the model using new tf.data API in TensorFlow. After setting the model and found the data, we can now start training.
Figure 2.2.1. The folder of the final corpus
2.3 Training
The training process requires certain environments including Python 3.6, NumPy, and TensorFlow 1.4 and NLTK (Natural Language Toolkit) version 3.2.4.
We set the batch size into 256, the source maximum length and the target maximum length are both 50 words. The probability we want to keep is set to 0.9.
With more than two days’ training, we come up with a model.
Figure 2.3.1. Start Training

Figure 2.3.2. Our final model
3. Result and Discussion
3.1 Results and testing
Although we can see loss and other indicators directly, it is still hard to measure how good the module is as its output is language which is hard to quantize. Here are some demonstrations with running the test program. The result is quite good and can basically reply to many kinds of questions.
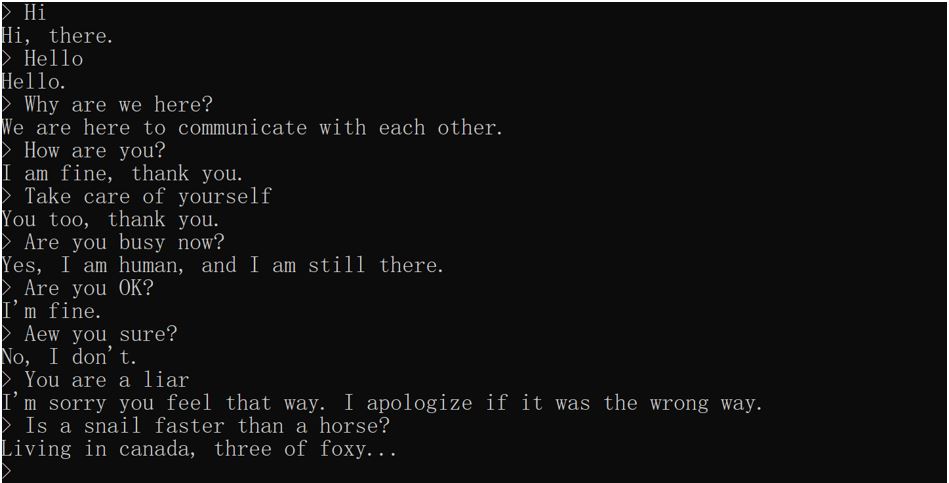
Figure 3.1.1. Demo test result
3.2 Discussion
In the way of implementing the model, we have tried three models including the model we are currently using. The first one is implemented in the original seq2seq model. And we developed the dataset by ourselves. As the dataset is too small, only contains about 30 pairs of chats, the result is not satisfactory. Also, the requirement of incoming data is quite wired, so we finally give up using this model.
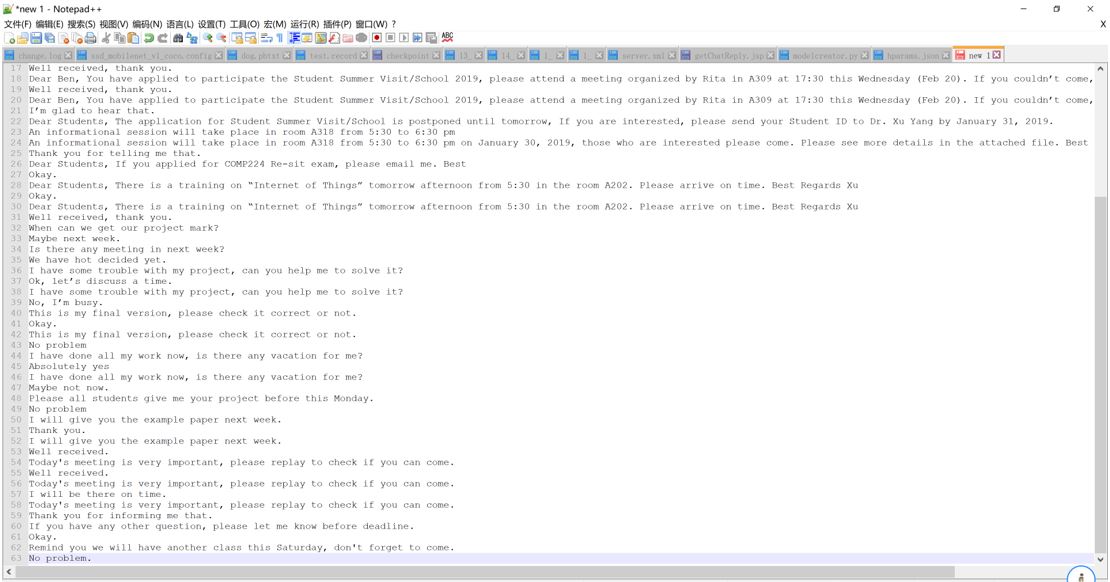
Figure 3.2.1. The original handcrafted corpus
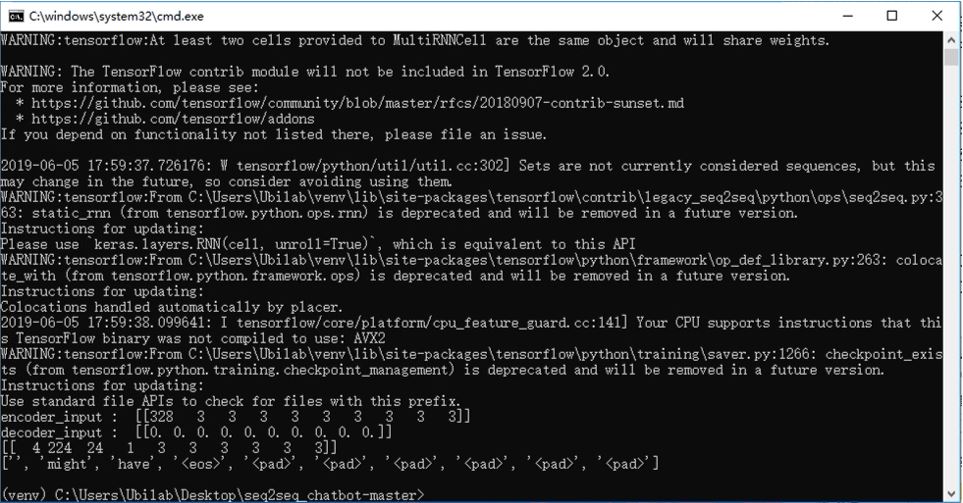
Figure 3.2.2. The testing results of the first model
Then we tried another model. This model is also using the seq2seq model, based on TensorFlow, which means we can easily implement the APIs offered by TensorFlow to process data and train the model. And in this model, we use the Cornell movies dataset to train the model. As this model is first developed by a paper of Google [4], we followed the steps in the paper strictly. Even with more than 100,000 steps of training, and the loss has decreased to a relativity low level, the test result is still not satisfactory.
We found a possible solution to solve why the two attempts don’t come up with satisfactory results. As a model has a capacity limit: how much data it can learn or remember. When you have a fixed number of layers, number of units, type of RNN cell (such as GRU), and you decided the encoder/decoder length, it is mainly the vocabulary size that impacts your model's ability to learn, not the number of training samples [5]. So, in this way, even with more than 100,000 steps of training, if the vocabulary set and the dataset is not good enough, there will still be trouble.
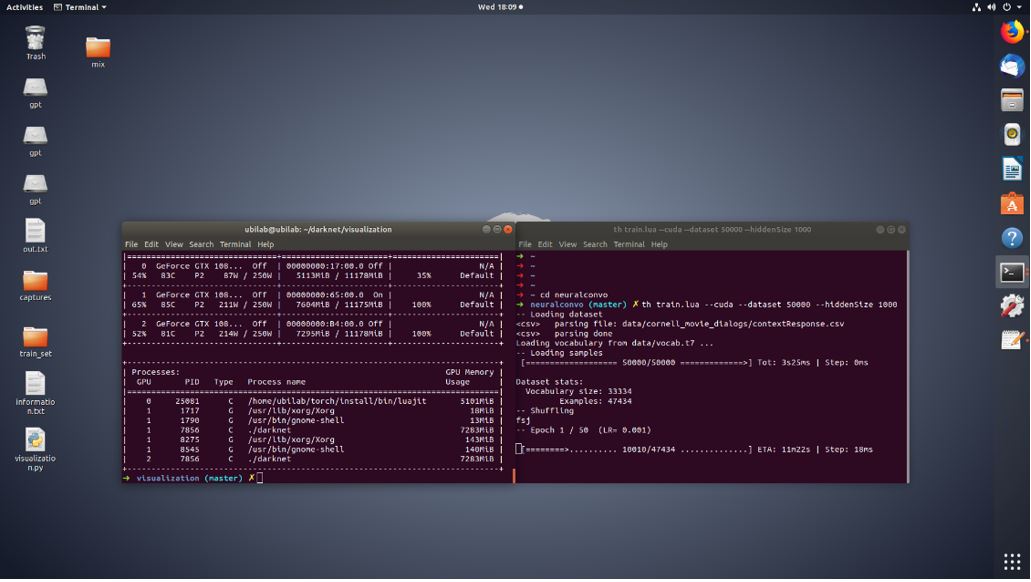
Figure 3.2.3. The training process of the second model
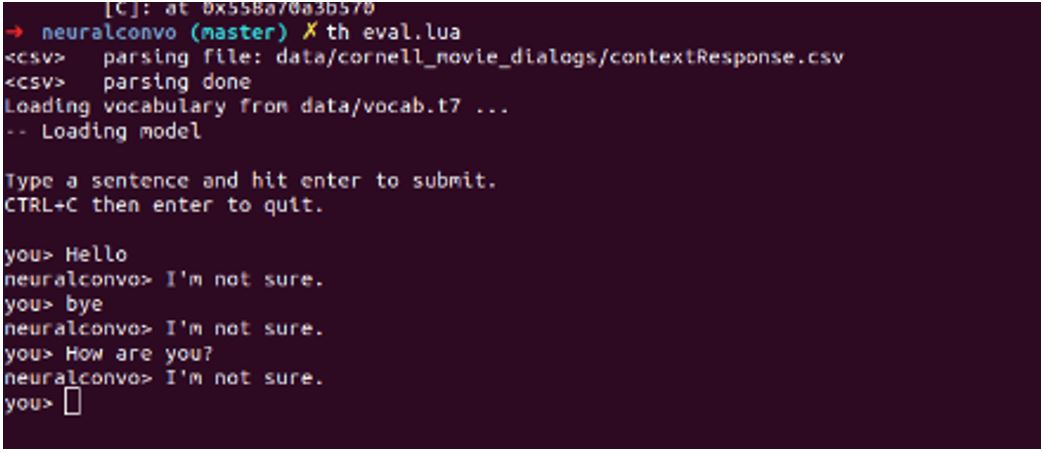
Figure 3.2.4. The testing results of the second model
So, we are currently using the new seq2seq model based on dynamic RNN (a.k.a. the new NMT model). This has several significant benefits like it is using the recent decoder / attention wrapper API, TensorFlow 1.2 data iterator, incorporating our strong expertise in building recurrent and seq2seq models, providing tips and tricks for building the very best NMT models and replicating Google’s NMT (GNMT) system [5].
4. Challenges and difficulties
During doing the project, we have found some problems. The first is which model to use. The first two models are based on the sequence to sequence model [6], but the results of them are not so good. So, we realized that the problems may not come from the models, but the dataset we used to train the models.
Then we put our focus on the selection of dataset. Previously, used a small dataset created by us. The quality of the corpus is relatively high, but due to the small number of words, the reply generated by this dataset is too simple and is unable to reply to any complex questions.
In this way, we changed our dataset to movie dialog [7], this dataset is much bigger than the first one, but the conversation style inside is not as similar as our daily communications.
We finally decided to use Papaya Conversational Dataset, which is large and close to real communications.
5. Conclusion and Further Work
5.1 Conclusion
We developed a smart reply bot which provides simple mail conversation reply, it can be integrated in a mail application as a smart mail replier. Besides this, its usage can also be extended to social software, people can also use this smart reply bot to reply short message quickly. The core of this system is a seq2seq model to predict full response with the given message. And it also has some basic detect function to point out nonsense. To our delight, the result of our project is quite satisfactory as it can reply to most of the basic daily chats.
5.2 Further work
In the future, we would like to deploy this model into a mobile app and then it can detect mail and give the related replies automatically.
Furthermore, we could design some method to let people can train the model with their own history message. That means people can use their history message as the dataset of model and using this dataset to re-train the model. If it works, everyone can have their own model then, the model could try to follow the user’s communication style, let the reply closer to artificial.
6. Reflection
In the past month, we march forward bravely in the ocean of machine learning. Even from zero to one is quiet suffering, but the knowledge we finally get still let us mad with joy. We were beginning with linear algebra and probability theory and then based on them we pay our focus on basic neural network theory. Especially in RNN and LSTM, we are not only learned the structure of their cells, but also practice them in real in our project. While processing our dataset, many problems happened, encoding error, format error and so on, we have tried many ways to filter dataset and at last we get the dataset which satisfy our requirement. Finally, after one month works, we are more familiar with TensorFlow APIs, and have the ability to develop our own models.
- Bo Shao. https://github.com/bshao001/chatlearner#papaya-conversational-data-set
- Thang Luong, Eugene Brevdo, Rui Zhao. https://github.com/tensorflow/nmt
- Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Networks. arXiv:1409.3215v3 [cs.CL] 14 Dec 2014
- Oriol Vinyals, Quoc Le. A Neural Conversational Model. arXiv:1506.05869v3 [cs.CL] 22 Jul 2015
- Bo Shao. https://github.com/bshao001/chatlearner#chinese_chatbots
- https://github.com/sea-boat/seq2seq_chatbot
- http://www.cs.cornell.edu/~cristian/Cornell_Movie-Dialogs_Corpus.html
Go To Report 2 >>>