Report 2 -- Object Detection
Advisors: Giovanni Pau, Rita Tse, Tan Wang
Group Members: Jennifer Chun, Monica Lyu
1.1 Background
Machine learning is the scientific study of algorithms and statistical models that computer systems use in order to perform a specific task effectively without using explicit instructions, relying on patterns and inference instead. And deep learning is part of a broader family of machine learning methods based on artificial neural networks.
Machine learning is one of today’s most rapidly growing technical fields, lying at the intersection of computer science and statistics, and at the core of artificial intelligence and data science. Our motivation is to get started with machine learning and learn about the basic process of object detection. TensorFlow is an end-to-end open source platform for machine learning. It offers multiple levels of abstraction, and the TensorFlow Object Detection API is an open source framework built on top of TensorFlow that makes it easy to construct, train and deploy object detection models. By using the high-level Keras API, we could get started with TensorFlow and machine learning easy. Therefore, we choose TensorFlow to start our study journey of machine learning.
1.2 Objectives and Main Tasks
We have two objectives. The first one is detecting some objects in the pictures, which realizes static object detection. The other one is detecting some objects by using mobile phone camera, which realizes dynamic object detection.
The main tasks are invoking TensorFlow object detection API and migrating the trained model to the mobile phone in order to achieve the objectives.
2. Design and Implementation
2.1 Environment Setting Up and Testing
Install Anaconda3 and choose the default python 3.7 version. Then deploy the related environment variables. In the Anaconda Prompt, use 'pip' to install the CPU and GPU version of TensorFlow. For the GPU version, the related CUDA Toolkit and CUDNN should also be installed. And a new conda virtual environment should be created. The name of the these two conda virtual environment here are tensorflow_cpu and tensorflow_gpu respectively.
To test the installation, the follows should be done: Open a new Anaconda Prompt window and activate the tensorflow_cpu/tensorflow_gpu environment. Start a new Python interpreter session by running ‘python’. And then running the following code.
If 'Hello, TensorFlow' is showed on the console, then the CPU/GPU version is installed successfully.
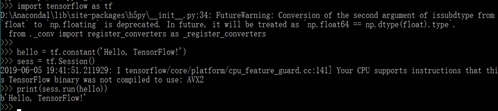
Image 1. TensorFlow has been installed
After setting up the required environment, it is time to install the required packages which are needed before installing the models. These pacakges are pillow, lxml, jupyter, matplotlib, and opencv. They can be installed by using conda. And then downloading TensorFlow models from the official website. Now the directory tree looks like such:
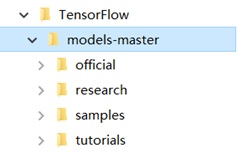
Image 2. The directory tree
The TensorFlow Object Detection API uses Protobufs to configure model and training parameters. Therefore, before the framework can be used, the Protobuf libraries must be downloaded and compiled. This should be done as follows: Downloading the latest Google Protobuf from its releases page. Extracting it and adding the path of its bin directory to the Path environment variable. And then in a new Anaconda Command Prompt, cd into TensorFlow/models-master/research/ directory. By using ‘protoc object_detection/protos/*.proto --python_out=.’ command, the related python file was generated for the proto file.
To test the object detection API, the command ‘python object_detection/builders/model_builder_test.py’ is used under the path models-master/research/. Then, the working directory should be changed to models-master\research\object_detection. Next, starting a new jupyter notebook server on the machine by using ‘jupyter notebook’, and then, opening the object_detection_tutorial.ipynb in the redirected page of the default browser. Running the code, the following picture will be shown.
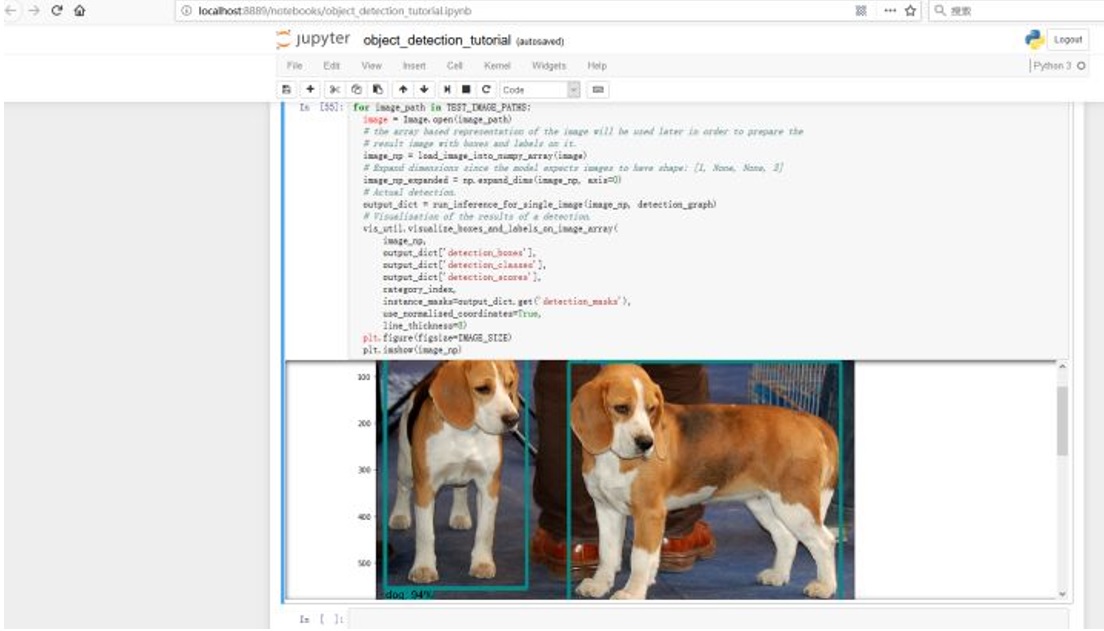
Image 3. The result of running object detection demo
2.2 Model Construction
Here a folder named images was created, which contains two sub-folders, named train and test. The images/train folder will be used to store the images that will be used to train our model. The images/test folder will be used to store the images that will be used to test our model.
For the first try, our purpose was to be familiar with the entire process of model creating, training, and migrating. Therefore, only a simple model was created regarding to easier to correct the mistakes. Our decision is to establish a model to detect a single person. Thus, we searched and picked some pictures of Cheng Xiao, a Chinese idol. Every picture was annotated by using the software LabelImg to generate the *.xml files, which contain the labels of the pictures and the position information.
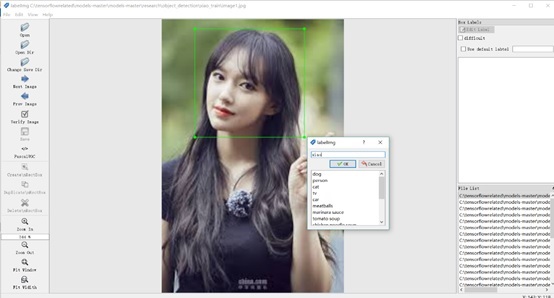
Image 4. Annotate the images
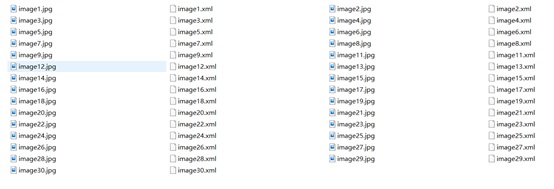
Image 5. The result of annotating the images
After annotating all the pictures, all the *.xml files need to be assembled into a *.csv file. Because the input data format of the TensorFlow object detection API is TFRecords format, the *.csv files needed to be transferred to the *.record files. A label map is also required, it namely maps each of the used labels to an integer value. This label map will be used in the process of training and detection.

Image 6. Label map for our first simple model
2.3 Model Training
In the model training section, we reused one of the pre-trained models provided by TensorFlow. The model we chose was ssd_mobilenet_v1_coco, since we want to migrate the model to the Android phone to realize dynamic object detection through the mobile phone camera, and this model provides a relatively good trade-off between performance and speed.
After choosing the pre-trained model, we need to get the sample pipeline configuration file for the specific model that will be re-trained. Here the corresponding file is ssd_mobilenet_v1_coco.config. Apart from the configuration file, the latest pre-trained NN for the model is also needed.
There are some changes need to be applied to the config file. Because we have only one label class this time, the num_classes should be set to 1. The related training path also need to be configured. The batch_size is the number of data per iteration. Due to the restriction of the equipment, it was set as 1.
Then it is the time to initiate a new training job. In the Anaconda Prompt, change the work directory to models-master\research\object_detection, and train the model by running the command ‘python legacy/train.py --logtostderr --train_dir=training/ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config’.
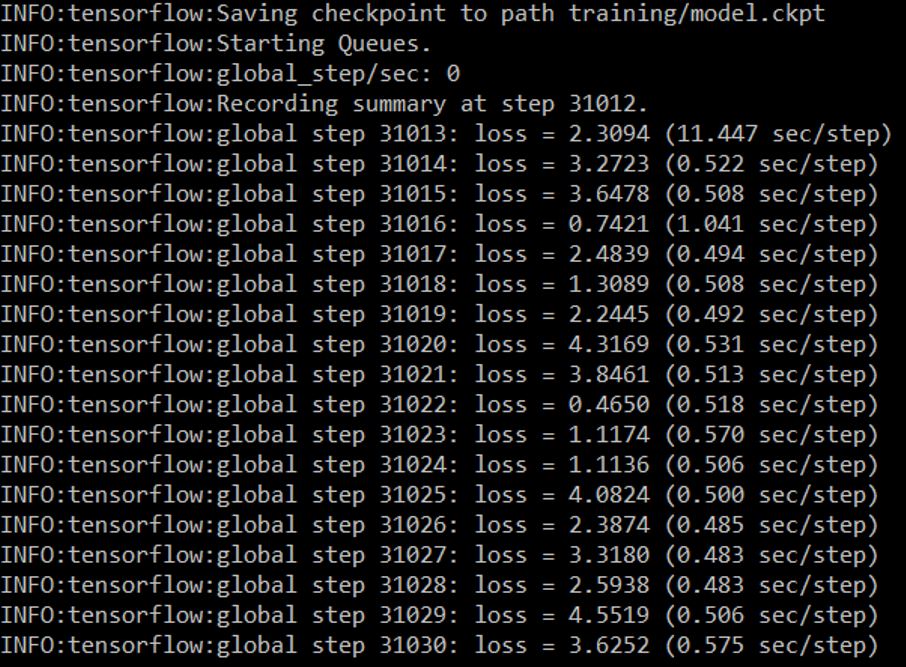
Image 7. The training process
The loss here refers to a number indicating how bad the model’s prediction was on a single example. If the model’s prediction is perfect, the loss is zero; otherwise, the loss is greater. The goal of training a model is to find a set of weights and biases that have low loss, on average, across all examples. Neural networks are tested using an optimization process that requires a loss function to calculate the model error.
The training times can be affected by a number of factors, such as the computational power of the hardware, the size of the dataset, the complexity of the objects, etc.
The optimization situation can be seen in the visual page. The method to call-out the visual page is to execute the command ‘tensorboard --logdir=training’ under the models-master\research\object_detection directory.
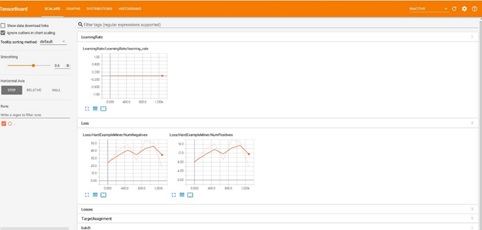
Image 8. The visual page
The process of training can be paused to see the current effect of the model. To export a trained inference graph, in the models-master\research\object_detection directory, run the command ‘python export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path training/ssd_mobilenet_v1_coco.config \ --trained_checkpoint_prefix training/model.ckpt-31012 \ --output_directory xiao_inference_graph’, where model.ckpt should be the checkpoint obtained from actual training.
Here the --output_directory is the folder name of the output model. After executing the command above, the xiao_inference_graph folder appeared in the object_detection.
Image 9. The xiao_inference_graph folder
2.4 Model Testing
Based on the code of the demo, we changed some details. Firstly, the model from the downloading model was changed to our own model, and the num_classes was changed to 1. Next, some test images were found and put in the test_images folder.
The following are the results of our model testing.
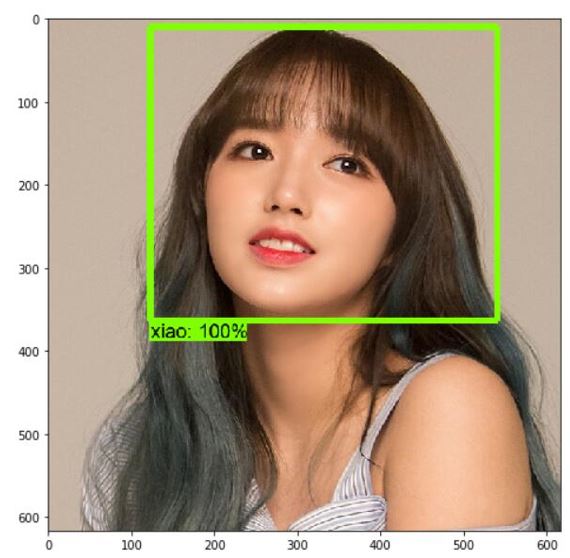
Image 10. Test result 1
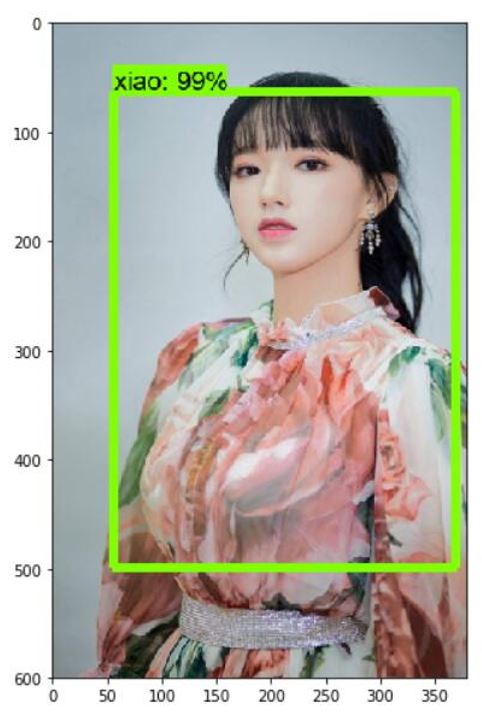
Image 11. Test result 2
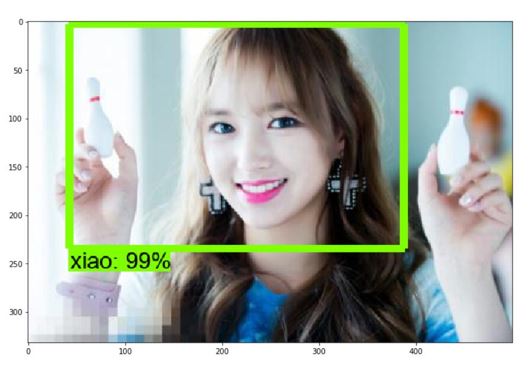
Image 12. Test result 3
If the training result is not accurate, we can continue the training process by using the checkpoint.
2.5 Model Enrichment
After the first try, we wanted to enlarged the model, so we annotated another 16 kinds of objects, which are people, car, laptop etc. However, the quantity of each kind of picture was too few. Even if the model has been trained 200000 times, when the test was been doing, it could not detect the object we have annotated. To deal with it, we found a dataset from the internet and started a new round of training and testing. And this time, we got the required results.

Image 13. The wrong result 1

Image 14. The wrong result 2

Image 15. The required result 1
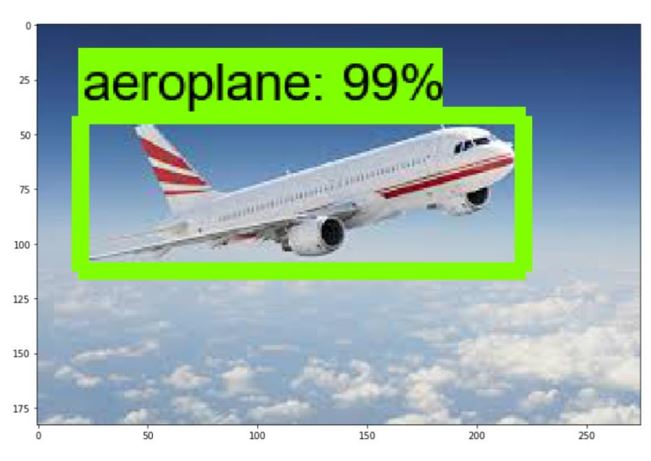
Image 16. The required result 2

Image 17. The required result 3
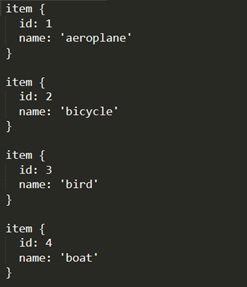
Image 18. Label map
2.6 Model Migrating
All the model mentioned above were trained based on the ssd_mobilenet, which is relatively light weight, so it could be used on the mobile phone.
To migrate the model, the first step is to install Android Studio and clone TensorFlow. Then in the build.gradle file, the nativeBuildSystem variable needs to be set as ‘none’. The next step is to put the *.pb file in the assets folder under the Android folder and to create a text file to store the related label information, which is consistent with the label in the training process. And then, in the DetectorActivity.java file, the TF_OD_API_MODEL_FILE and the TF_OD_API_LABELS_FILE variable should be set to the path to the model and the path to the label text file respectively.
After finishing all the setting, we could migrate the model to the Android mobile phone. The dynamic object detection is available now.
3. Result and Discussion
After migrating our model to our mobile phone, we tried to use it to detect the object through the mobile phone camera. The following pictures are the results of our project.

Image 19. Project result 1

Image 20. Project result 2

Image 21. Project result 3
However, sometimes the results are not acceptable. To optimize it, we found that in the DetectorActivity.java file, the MINIMUM_CONFIDENCE_TF_OD_API variable refers to the confidence level of the object. The higher the value of this variable, the more exact the frame.
This is the result when we set the value of the MINIMUM_CONFIDENCE_TF_OD_API variable to 0.1.
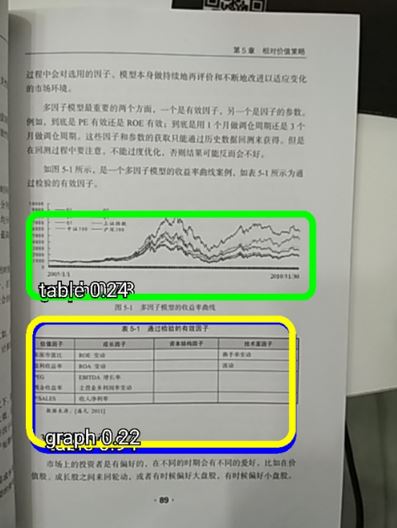
Image 22. The result of changing value to 0.1
This is the result when we set the value of the MINIMUM_CONFIDENCE_TF_OD_API variable to 0.6.
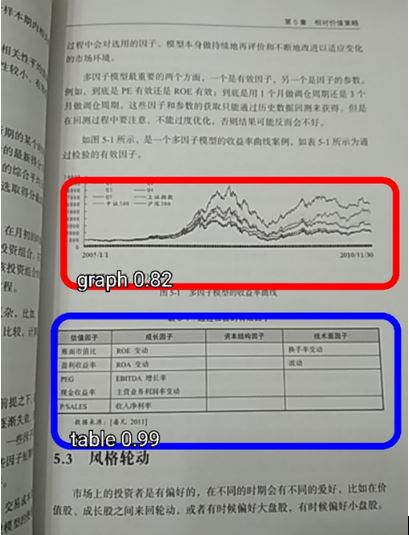
Image 23. The result of changing value to 0.6
4. Conclusion and Further Work
In conclusion, we went through how to reuse one of the pre-trained models provided by TensorFlow to trained our own model and used TensorFlow object detection API to realize our two objectives.
In this project, we learned the process of object detection in machine learning by creating our own model and invoking the object detection API of TensorFlow. We also reviewed and applied the linear algebra when we created and trained the model. Moreover, we figured out the basic realization process of Neural Network.
For the further work, we would like to try to train an entirely new model, to create a training job from the scratch, and to try to do the Instance Segmantation.
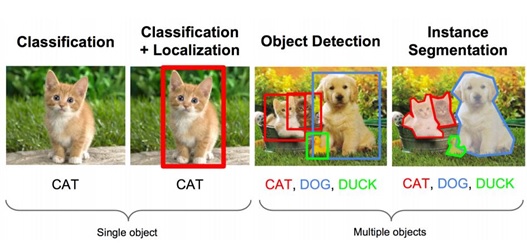
Image 24. Type of Object Detection
5. Reference
- https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/
- http://jultika.oulu.fi/files/nbnfioulu-201802081173.pdf
- https://machinelearningmastery.com/loss-and-loss-functions-for-training-deep-learning-neural-networks/
- https://developers.google.com/machine-learning/crash-course/descending-into-ml/training-and-loss
- https://blog.csdn.net/dy_guox/article/details/80192343
- https://zhuanlan.zhihu.com/p/35854575
- https://www.tensorflow.org/