
1.1 Overview:
We were joining a summer exchange student program in ubiquitous computing which is held by MPI and UCLA. We were required to analyze the topics in which people mentioned in SinaWeibo last year. The data for analysis is from MySQL server which collects a tweet every 2 minutes. Firstly, programs written by Pythonare used to connect to the server for fetching data. Then the data was exported in text file format. Secondly, the data needs go through the transformation process before analysis. Finally, we could find out the extent of popularity for some specific topics, prediction of topic in which people are intend to say and percentage of topics that specific people are interested in.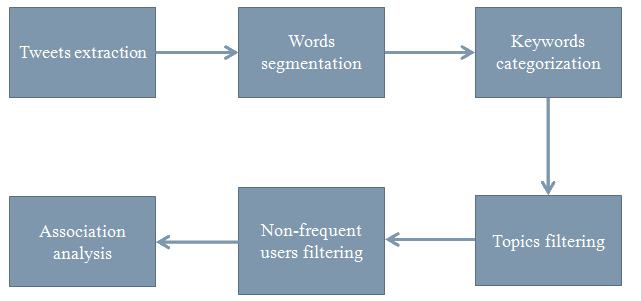
1.2 Tools:
- Programming language: Python, JAVA
- SDK: Eclipse, Weka
- Database: MySQL database
Data mining is the analysis step of the “Knowledge Discovery in Database”. There are many steps prior to data mining. The steps we have gone through will be illustrated in the following paragraphs. As a result, we could find out the association of keywords under a topic.
2.1 Data Selection:
Users who tweet over 50 times in Macao were selected and their whole micro blog was collected last year. Using Python MySQLdb connect to MySQL to scratch the data into hard disk. Use bash, AWK & SED to process data, as a result of dividing the whole data into documents and each named by their id.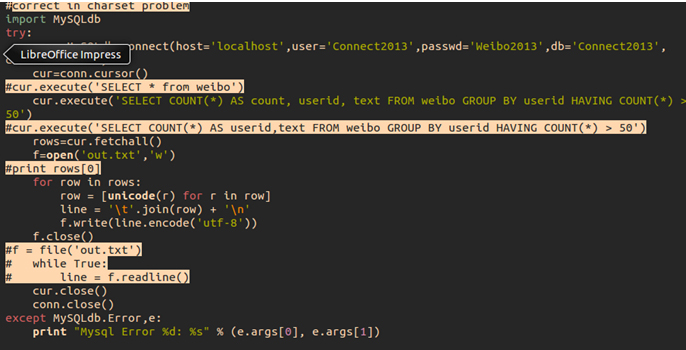
2.2 Data processing:
The extracted data from micro blog contains not only Chinese characters, but also another characters such as symbols, numbers and English as shown above. Therefore, we need to filter out those non-Chinese characters and remain Chinese nouns for the preparation of LDA model classification.2.2.1 Word segmentation:
There are several approaches to perform text segmentation. NLPIR and ANSJ were used in this project.NLPIR:
In order to find out the topics, all the irrelevant verbs and symbols etc. are needed to be filtered out. Therefore, we use NLPIR, natural language processing library for information retrieval by invoking NLPIR_JNI.dll and NLPIR.dll. According to its development document, we can use JNI interface to achieve word segmentation. According to the document for flags of Chinese part-of-speech patterns, sentences are separated into words with the flag behind. Since the limitation of NLPIR, it couldn’t recognize some specific addresses, product names etc. So we need to import a user-defined dictionary for accurate classification. After this segmentation process, all the words will be flagged. Then, we can apply regular expression to remain the nouns in the text file.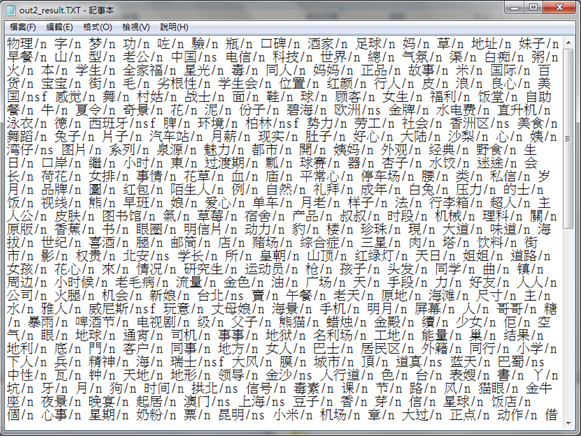
Result of NLPIR segmentation
ANSJ:
Our group also wrote another type of segmentation program which based on ANSJ Chinese Words Segmentation tool. The program can filter out words that are irrelevant to nouns such as verbs, punctuations, adjectives and so on. The relevant words such as the people’s names, address names and product names will be kept. Considering the dictionary of ANSJ does not contain the specific words in Macao such as names of Casinos, street of Macao, names of shopping malls and so on, we built a user dictionary for the segmentation program.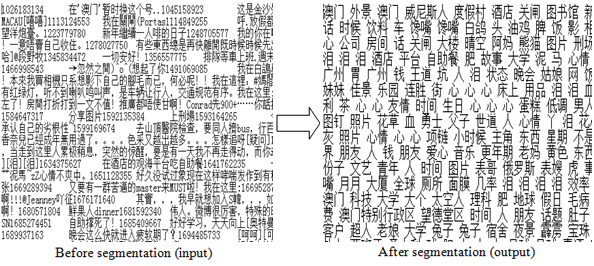
2.2.2 Word categorization:
Having the document containing nouns, then we can apply a tool named GibbsLDA++ to categorize the nouns into 50 different topics. In this step, we run LDA command ($ lda -est 0.5 0.1 50 1000 100 20 all.dat) to categorize keywords into topics. After 1000 iterations, 50 different topics are generated by this modal and each topic contains 20 most likely words with its probability of appearance.2.3 Filtering meaningless topics and optimization of keywords:
Having the execution of LDA model, 50 different topics are generated. However, some of these topics are meaningless. Hence, we have to filter out the meaningless topics manually. Eventually, we obtained 5 meaningful topics. The next step is to optimize the association of keywords under each topic. Therefore, the irrelevant keywords will be eliminated.2.4 Filtering non-frequent users:
In this step, we would like to find out the frequent users under a topic. Hence, we need to find out the users whose probabilities of mentioning a topic are more than 50%. Topic 41th is corresponding to the AQ column in this file and the column A is corresponding to the indices of users’ id.
2.5 Result of filtering process:
- Topic 3rd: Buddhism, No. of users: 1
- Topic 10th: Emotional icon, No. of users: 26
- Topic 21st: Hotels, No. of users: 5
- Topic 36th: Political, No. of users: 4
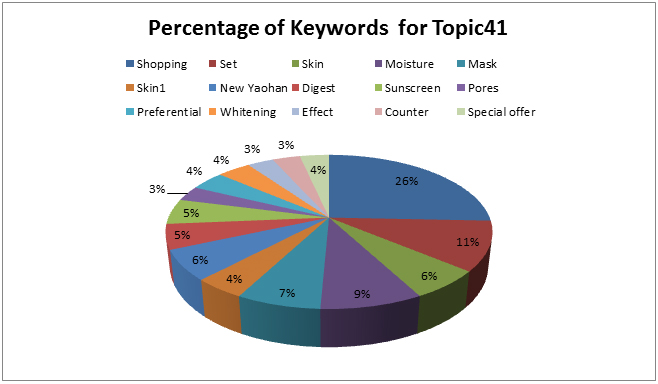
- Topic 41st: Skin care, No. of users: 21
2.6 User mapping list:
Once the non-frequent users were filtered out, we could use the user mapping to find out the frequent users’ id in a topic. The mapping list contains quantity of tweets and user id.2.7 Construction of CSV file:
Having users' id and meaningful topics, we can now construct CSV files for analysis of each topic by program, in this project, 4 CSV files were constructed in total. The first row of CSV file are the keywords under each topic, the first column is the indices of users' id. The rest of cells are the quantity of mentioned keywords. How many times a keywords was mentioned, how many ‘Y’s would be assigned for a keyword.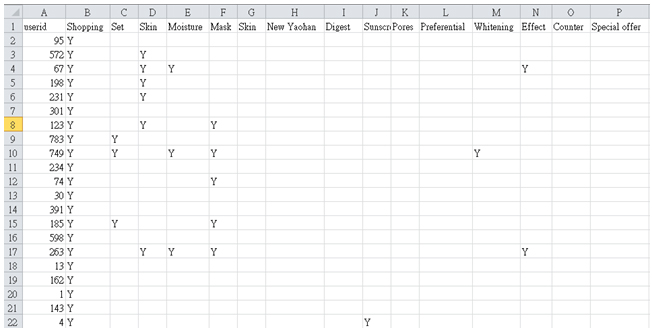
Having these CSV files containing keywords and users’ indices for a topic, we can move to data analysis process. After all the processes above, we can now use Weka to perform data mining by Apriori algorithm.
3.1 Transformation:
Firstly, we convert the CSV file to ARFF file which supported by WEKA.3.2 Parameter setting:
Secondly, we need to set the parameters of associate rules. We set the minimum support to 1% and the metric type to lift.
3.3 Result of association analysis:
Finally, we obtained the association result of keywords under a topic. Because the minimum support was set to 1% (40 instances for this example) which means any combination in itemsets whose frequency is less than 40 will be removed.3.4 Result of keywords association for Topic 41:
Based on the association result of topic41, we can make a conclusion for topic41:
- There are 21 users whose probability of using keywords in this topic is more than 50%.
- The association set containing three keywords (Shopping, Set, New Yaohan) from the 21 users’ tweets is the only one association set in Large Item sets L (3) which the frequency is greater than 42.
- The tweets from the 21 users containing keywords ‘Shopping’ and ‘Set’ have 52% probability containing keyword ‘New Yaohan’.
- The tweets from the 21 users containing keyword ‘New Yaohan’ have 27% probability containing keywords ‘Shopping’ and ‘Set’.
- The tweets from the 21 users containing keyword ‘Set’ have 16% probability containing keywords ‘Shopping’ and ‘New Yaohan’.
- There are 21 users whose probability of using keywords in this topic is more than 50%.
- The tweets from the 21 users containing keyword ‘Shopping’ have 56% probability containing keywords ‘New Yaohan’ and ‘Set’.
We could perform target marketing based on this analysis result above.
