- 1. Introduction
- 2. Automatically get token and code
- 3. Connect to the Database
- 4. Search the tweets and followers
- 5. GUI interface
- 6. File split and word segmentation
1.1 Overview:
We had the honor to join in the student exchange program which held by UCLA and MPI. During that time, we were required to design a sina weibo crawler to fetch data from servers and store it in the database with the help of sina weibo API. The whole program should achieve the following functions. First of all, the crawler is able to get access token automatically and fetch data of some specified user IDs to push them into mongo database. Secondly, we can search all the followers of an ID. In addition, our program supports keyword searching which is useful to data analysis.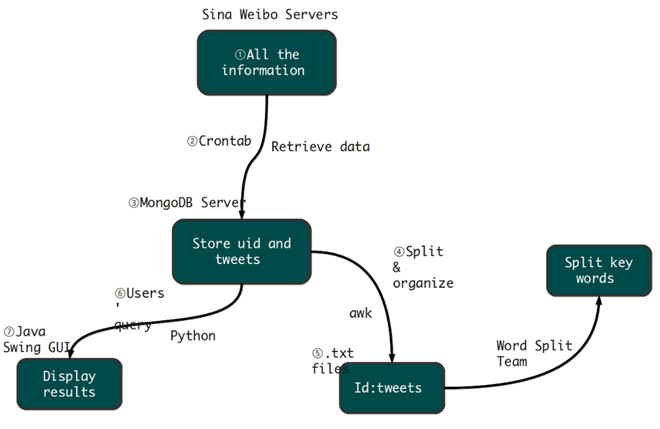
Sina Weibo is a data center for all the related user data and tweets, we invoked weibo API to retrieve the id and tweets from each user by python. We put python script into crontab to make it run automatically every day.
1.2 Tools:
- Programming language: Python, Java, bash, awk
- IDE: IDLE, NetBeans, vim, bpython
- Database: Mongo database
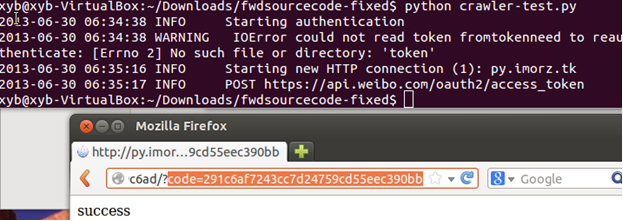
This is the main python program which invokes other subprograms and log files to get token and save it to a file named token. Due to the limit of our account, we need to renew our account every day. As a result, this program is really useful to the crawler.
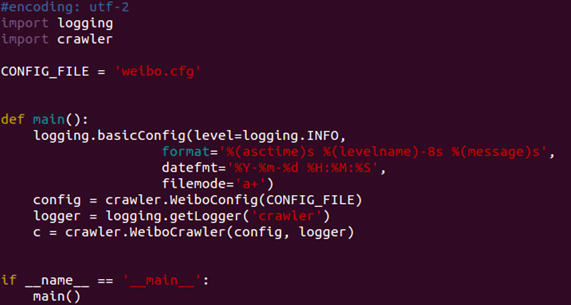
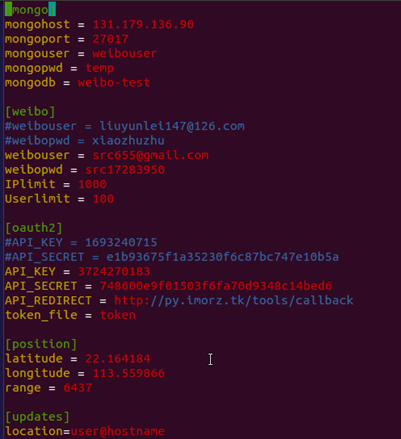
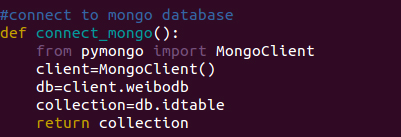
We use MongoDB as our database for two reasons: firstly, MongoDB is very easy to use and we don't need to care about SQL statements. Secondly, MongoDB relatively has higher performance over other DBMS.
4.1 Search the tweets of a given id:
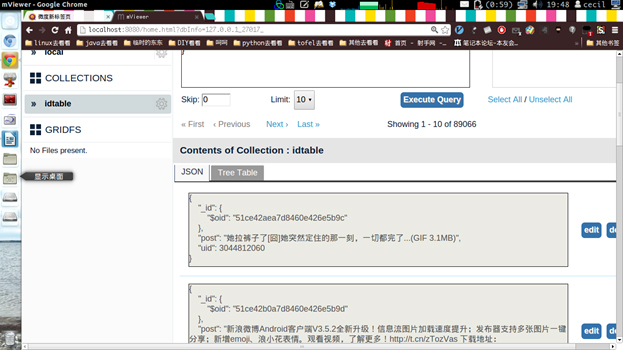
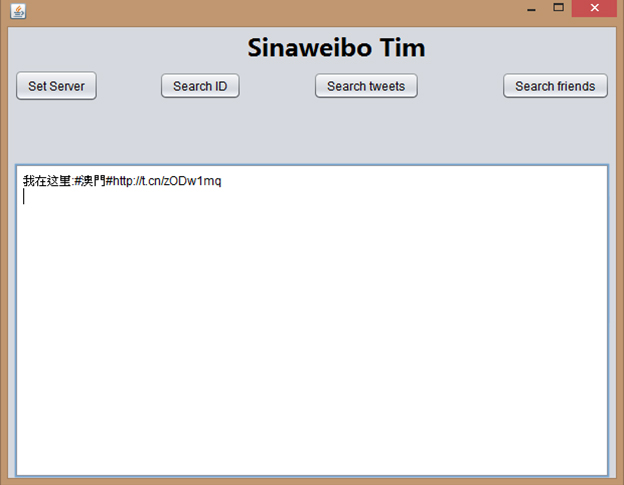
This function is used to search the tweets of a specific user by giving his or her user id. Firstly, we will search the tweets in our database, if we can’t find anything in the database, we will directly go to the weibo server to do searching.
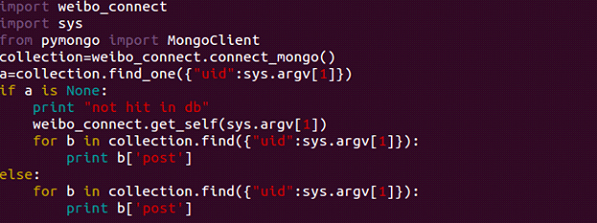
4.2 Search user ID and their followers:
The following code is used to search all the user ids that matches the numbers we input.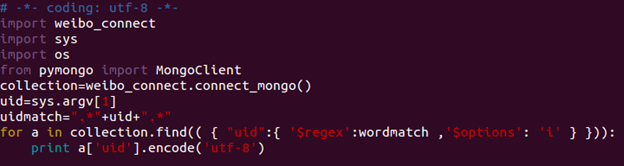
4.3 Search the tweets that matches the words:
This code shows the function of searching all the tweets that contains the words. Due to the account limitation, we will only search the tweets in our database rather than wasting a lot of time searching them online.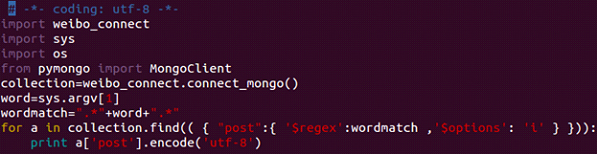
We build a java swing GUI program to display the result more clearly and friendly. It make our functions much easier to use.
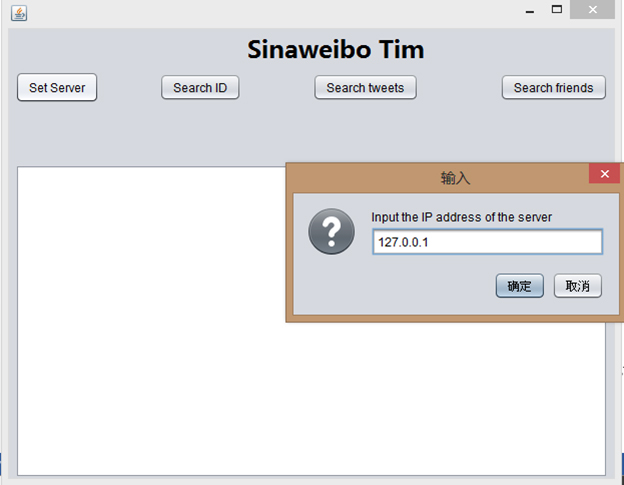
You need to set the mongoDB server first in advance in order to fetch the data. Here, I set the server on my local virtual computer and do the port forwarding.
6.1 File split:
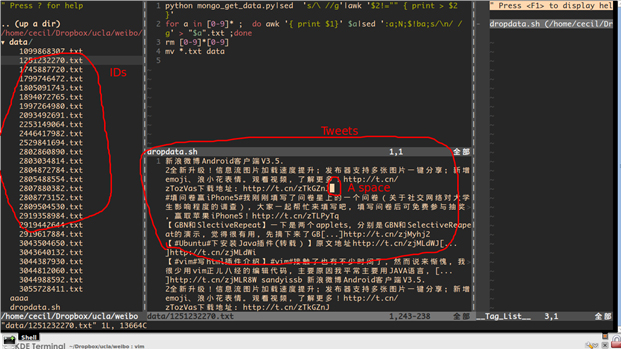
AWK is very powerful pattern scanning and processing language. Combined with other bash commands such as paste , sed … Data splitting and formatting is quite an easy job.
6.2 Word segmentation:
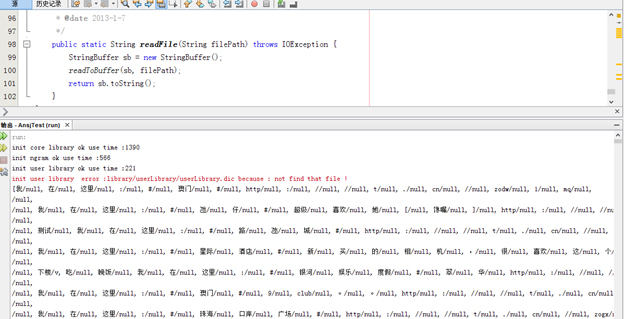
Our group wrote a program which is based on ANSJ Chinese Words Segmentation tool. The program can filter out words that are irrelevant to nouns such as verbs, punctuations, adjectives and so on. The relevant words such as the people’s names, address names and product names will be kept. Considering the dictionary of ANSJ does not contain the specific words in Macao such as names of Casinos, street of Macao, names of shopping malls and so on, we build a user dictionary for the segmentation program. Those are the effect after the word segmentation. Each sentence in each tweet is divided into separated words.